교육을 들으러 가는 오늘 아침은 눈이 많이 왔다.
다들 조심히 출/퇴근 하시길 바란다.
웹 크롤링, 스크래핑:
- 웹사이트에서 데이터를 자동으로 가져오는 기술을 말한다
- 검색 엔진도 크롤링 및 스크래핑을 활용해 정보를 수집한다.
둘의 차이라고 한다면,
크롤링: 여러 웹페이지를 탐색하면서 정보를 가져옴
스크래핑: 특정 웹페이지에서 필요한 데이터만 추출함
크롤링은 바닥을 기어 가면서 모든 것을 빨아들이는 청소기 같은 개념, 스크래핑은 Book Scrap과 같은 개념으로 이해했다.
정보를 수집하기 위해, robots.txt를 사용한다. 설명을하자면
- 액세스 하거나 정보수집을 해도 되는 페이지를 알려주는 파일
- 검색엔진은 해당 텍스트 내용을 기반으로 허용되지 않는 페이지로부터 정보수집을 하지 않음
예를 들어, http://naver.com/robots.txt 를 하게 된다면 네이버에서 지정한 허용범위를 알 수 있다. (경고판 느낌)

이때, 요청을 하며 User-Agent에 대한 개념도 나온다.
- HTTP 요청 헤더의 일부로, 사용자가 사용하는 브라우저나 기기의 정보를 서버에 전달하는 문자열
- 웹사이트 서버는 이 정보를 통해 요텅을 보낸 주체가 웹, 모바일, 봇 인지를 식별한다
----> 계속 response를 하면 사이트에서 디도스를 의심하므로 사이트 서버에 내 정보를 알리는 기능이라고 이해했다.
주로, headers = {"Users-Agent":"Mozilla/5.0(Windows NT 11.0; Win64; x64)"}
ex) response = requests.get(url = url_naver, headers=headers) -> 네이버에 User-Agent 개념을 탑재하여 요청한다.

또한, requests 라이브러리를 활용하여 정보를 수집할 수 있다.
기본적으로, 웹페이지 데이터를 가져오기 위한 HTTP 요청 라이브러리로 get(), post() 요청을 사용한다.
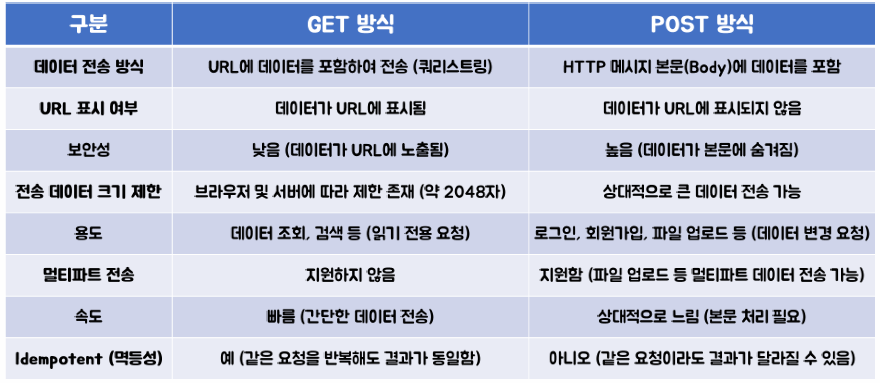
get은 query string 방식으로 URL에 데이터가 존재하고, post는 데이터가 URL에 포함되지 않는 것이 큰 차이점이다.
requests 라이브러리를 활용한 예제이다.
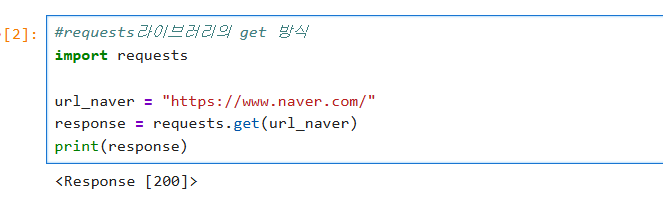
네이버의 url을 통해 홈페이지 HTML을 가져오기 위해 요청을 보낸다. 출력하면 [200 = 승인]을 응답 받는다.

이러한 상태들에 관한 오류를 예외 처리하는 예제도 다뤄보았다.
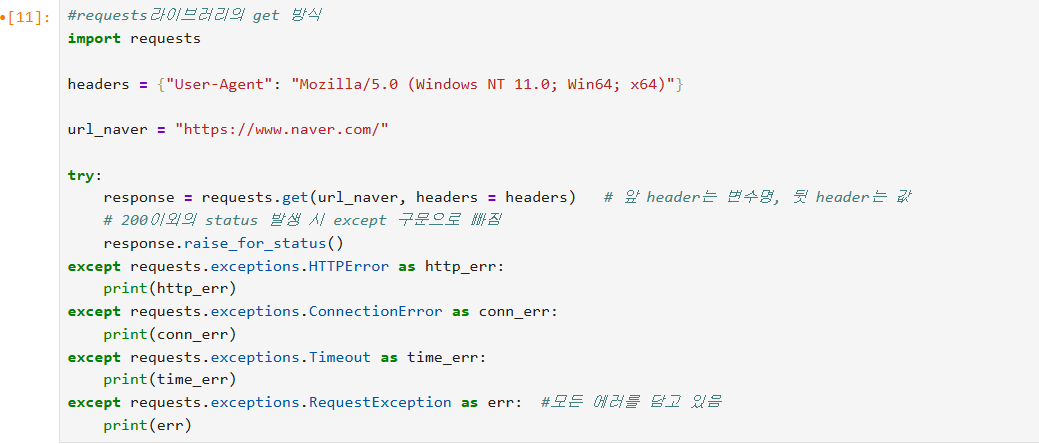
requests를 통해 response 승인을 받아 얻은 데이터를 처리하는 방법
1) response.text : 응답 본문을 문자열로 반환
2) response.content : 응답 본문을 바이트로 반환
3) response.json() : 응답 본문을 딕셔너리로 변환
정보수집에 대한 또다른 라이브러리 - BeautifulSoup - HTML/XML을 파싱해 데이터를 쉽게 추출한다.
주로, find(), find_all() 매서드를 활용해 특정 태그를 검색한다.
find("태그")를 통해 태그를 찾고, 첫번째 요소를 가져온다. 이후, .text를 통해 텍스트 형식으로 추출한다.
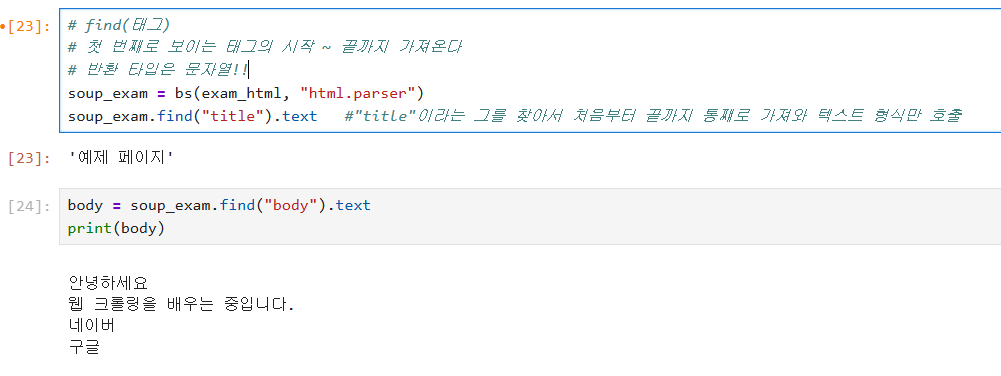
find_all("태그")를 통해 태그가 포함된 모든 요소를 반환한다. 이때, 태그는 <"태그명">의 형식을 지닌다.

선택자를 활용해 데이터를 가져올 수도 있다.
형태 : select(.클래스명)
ex)
news_title_list = soup_news.select(".sa_text_strong")
for i in range(5):
print(news_title_list[i].get_text())
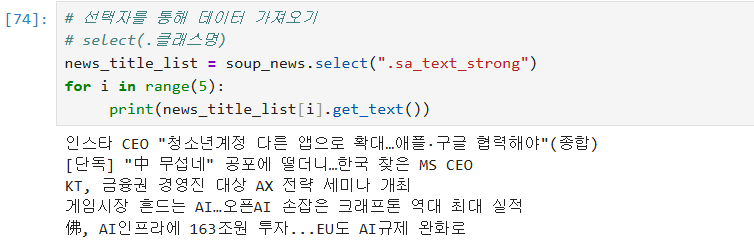
이를 활용해 특정 키워드를 지닌 기사의 제목을 가져오기도 할 수 있다.
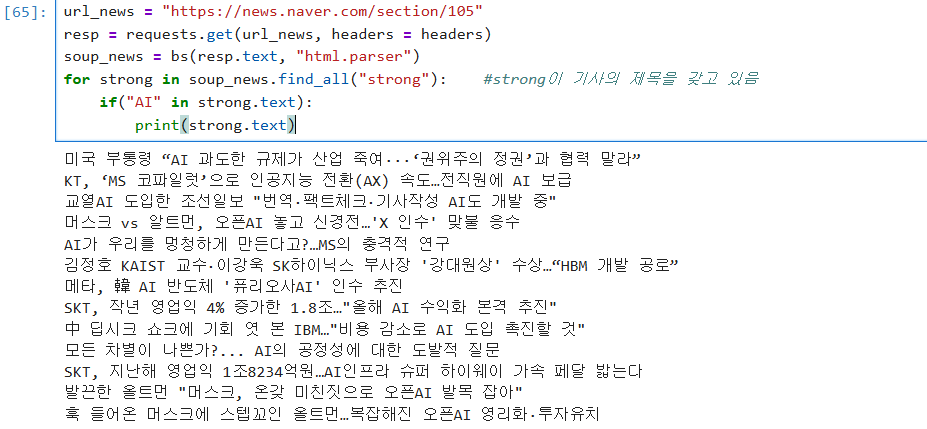
이에 대한 예제로, 네이츠 홈페이지의 오늘 날짜 기준, 약 10시경 1-10페이지에서 "AI" 단어가 있는 기사 제목을 추출했다.
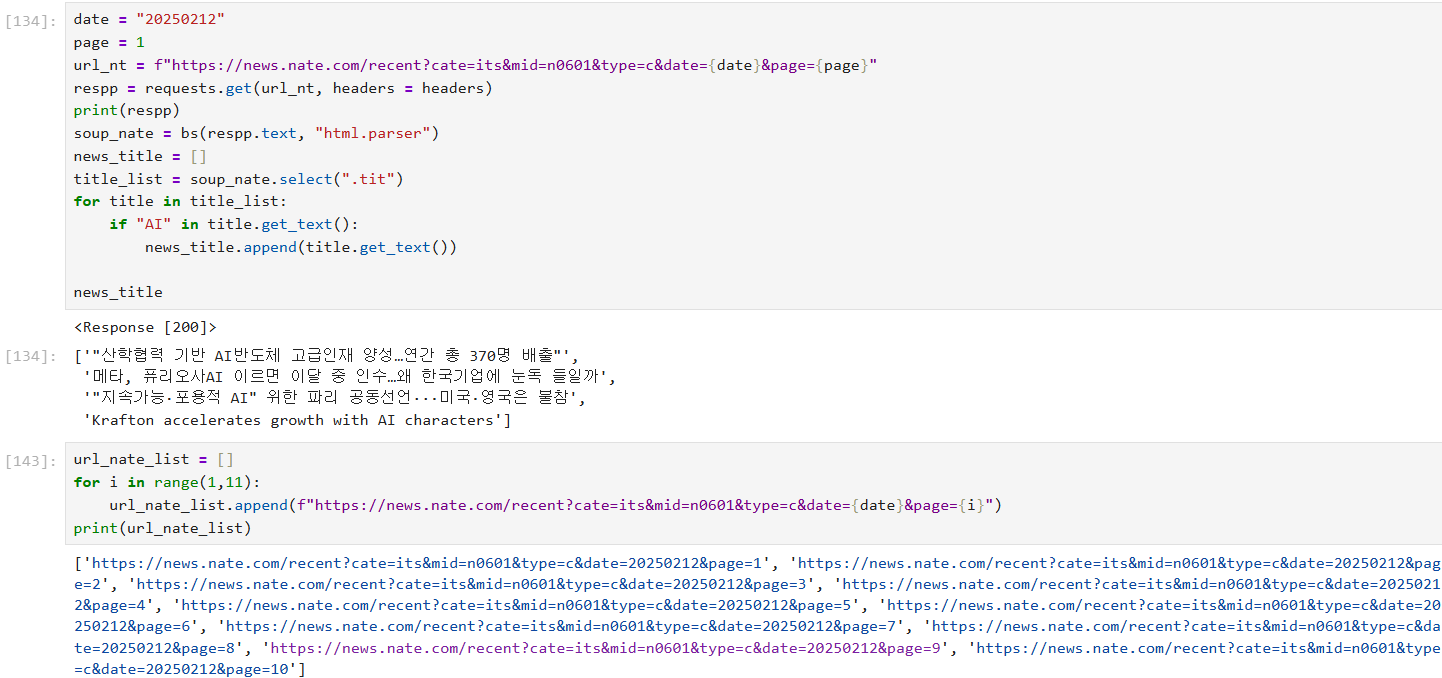
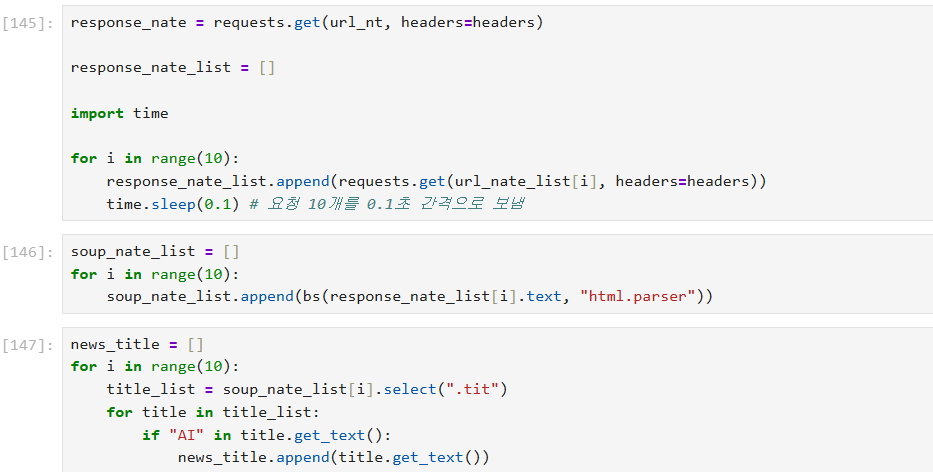

HTTP:인터넷에서 하이퍼텍스트 문서를 교환하기 위해 사용되는 통신 규약
Hyper Text : 현재 문서에서 다른 문서로 즉시 접근할 수 있는 텍스트
HTML (Hyper Text Markup Language) : 웹 페이징에 정보를 담아 표시하기 위한 **마크업 언어**
ㄴ 형태 : <시작태그> 요소 </끝태그>
<시작태그 = "속성"> 요소 </끝태그>



이러한 구조의 Body의 태그 속성 부터 배워야 한다.
이를 활용하여 HTML을 이용한 웹페이지, 표 등을 이쁘게 꾸밀수 있다.

- 제목 태그: html문서 본문 내 제목을 표현하는 태그
ㄴ ex) <h1>안녕하세요</h1>
- 글자 태그:
ㄴ 본문의 내용을 단락을 표현하는 태그
ㄴ ex) <p> 본문 </p>
ㄴ 본문의 내용을 문장으로 표현할 떄 사용하는 태그
ㄴ ex) <span> 본문 </span>
ㄴ ****스판코드는 띄어쓰려면 </br>필요
- 문단 태그: 시작 끝 없이 단독으로 사용
ㄴ 줄 바꿈 태그 : <br/>
ㄴ 단락 구분 태그, 수평선 태그 : <hr/>
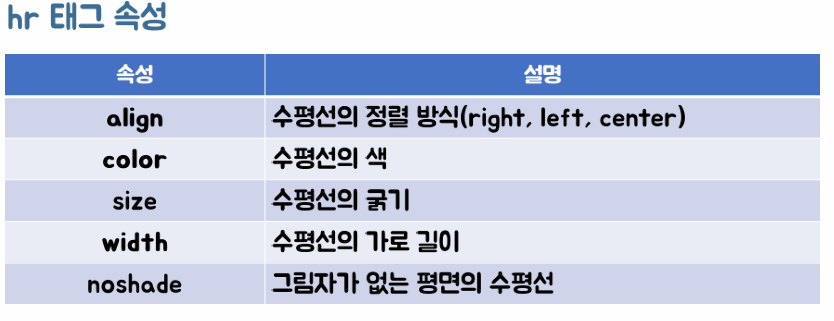
- 글자 태그 :
ㄴ 다른 텍스트와 구별할 때 사용되는 태그 : <b> 텍스트 </b> , 시각적 강조 태그
ㄴ 중요한 문구를 강조하는 태그 : <strong> 텍스트 </strong> ,
- 리스트 태그:
ㄴ 번호 없는 목록을 사용할 때 사용하는 태그 : < ul>, 정돈되지 않은 리스트
ㄴ 번호 있는 목록을 사용할 때 사용하는 태그 : < ol> , 정돈된 리스트, 넘버링이 붙음(type) 사용해서 변환
ㄴ 공통적으로 사용되는 태그 : < il>
- 이미지 태그: 웹 페이지에 이미지를 보여주는 태그
- a 태그 : 웹 페이지에 이미지를 보여주는 태그
형태 : <img alt "" , src = "" ...>

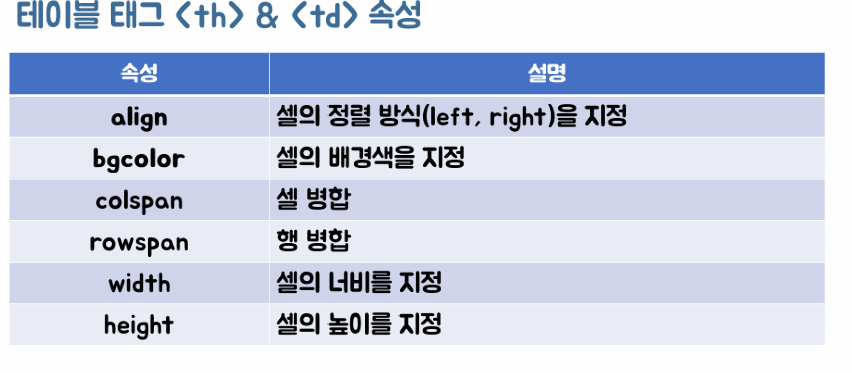
- 테이블 태그 : 테이블/표를 만들기 위해 사용함
ㄴ 행의 head 역할을 하는 태그
ㄴ <th> 태그 </th>
ㄴ table data, 칸 안의 데이터를 나타낸다.
ㄴ <td> 태그 </td>
ㄴ 표 내부에서 1줄을 생성하는 태그로, table row의 준말
ㄴ <tr> 태그 </tr>
위에 작성한 태그 속성들을 코드와 html로 생성된 결과를 보이겠다.
1) 웹 페이지를 만들어보자~~!
실행 코드:
<html>
<head>
<title>예제 페이지</title>
</head>
<body bgcolor="#ff69B4">
<h1>안녕하세요</h1>
<h2>방갑습니다</h2>
<h3>점심은 짜장면</h3>
<h4>을 먹습니다</h4>
<p class="text">웹 크롤링을 배우는 중입니다.</br> -><br>문단태그로 탭침
<!-- </hr> 수평선을 긋는 태그 -->
<hr color="red" size="140" width="150"></hr> - ><hr>에 수평선조건 넣기
<hr color="orange" size="120" width="150"></hr>
<hr color="yellow" size="100" width="150"></hr>
<hr color="green" size="80" width="150"></hr>
오늘은 눈이 조금 옵니다.</p>
<a href="https://www.naver.com">네이버</a>
<a href="https://www.google.com">구글</a>
</body>
</html>
결과:

2) 글자태그
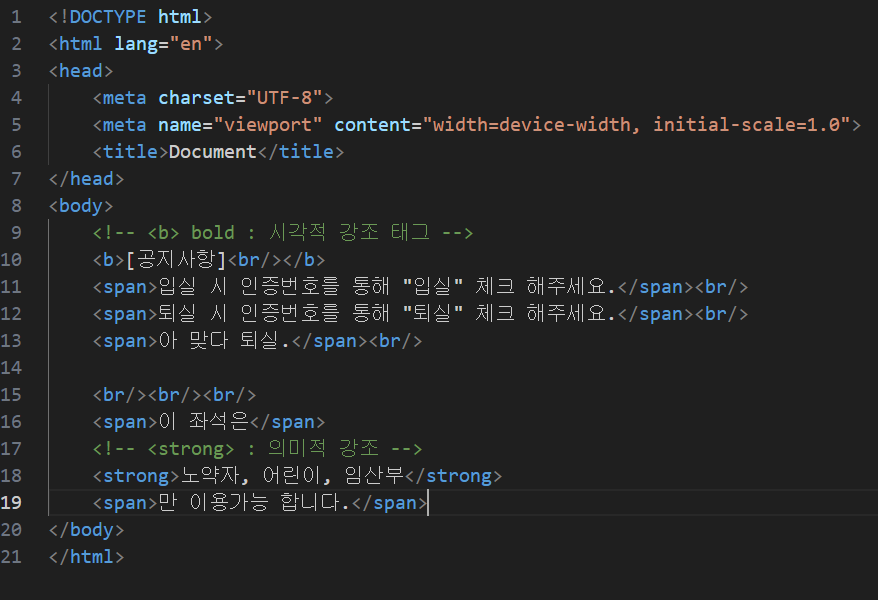
결과:

3) 리스트 태그
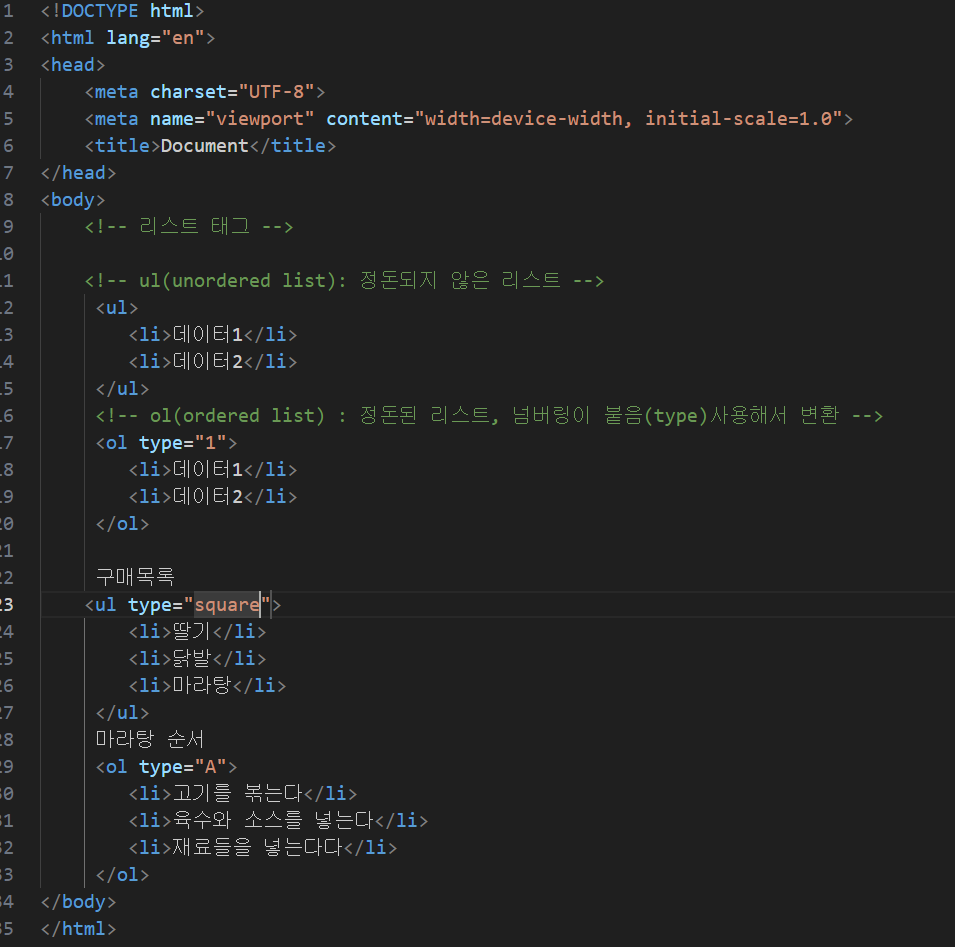
결과:

4) 이미지 태그
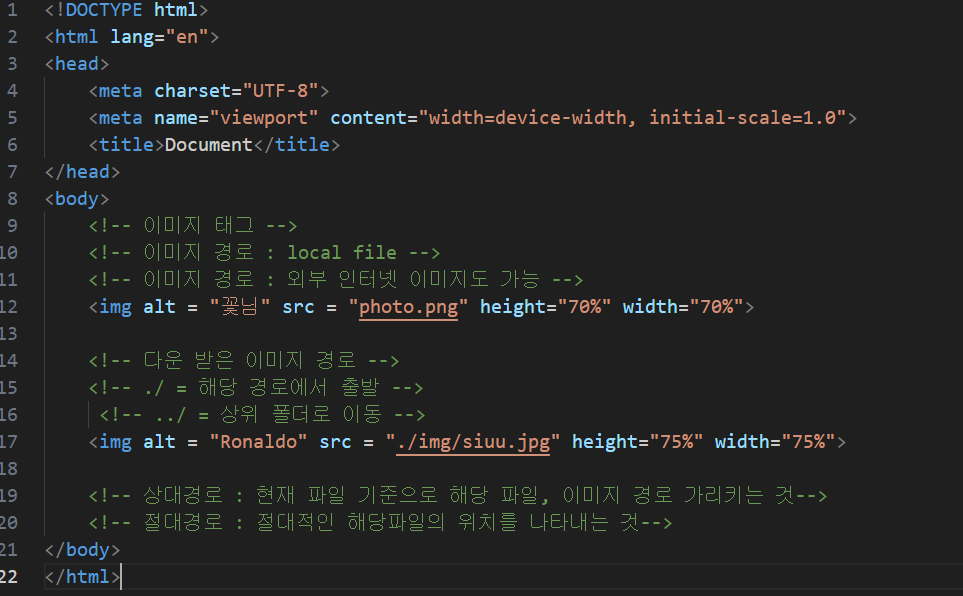
결과:

5) a 태그
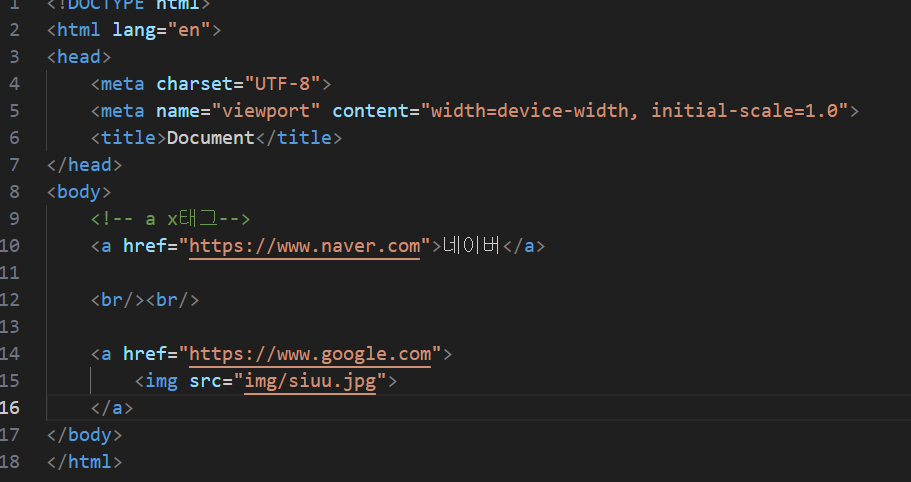
결과:

6) 테이블 태그
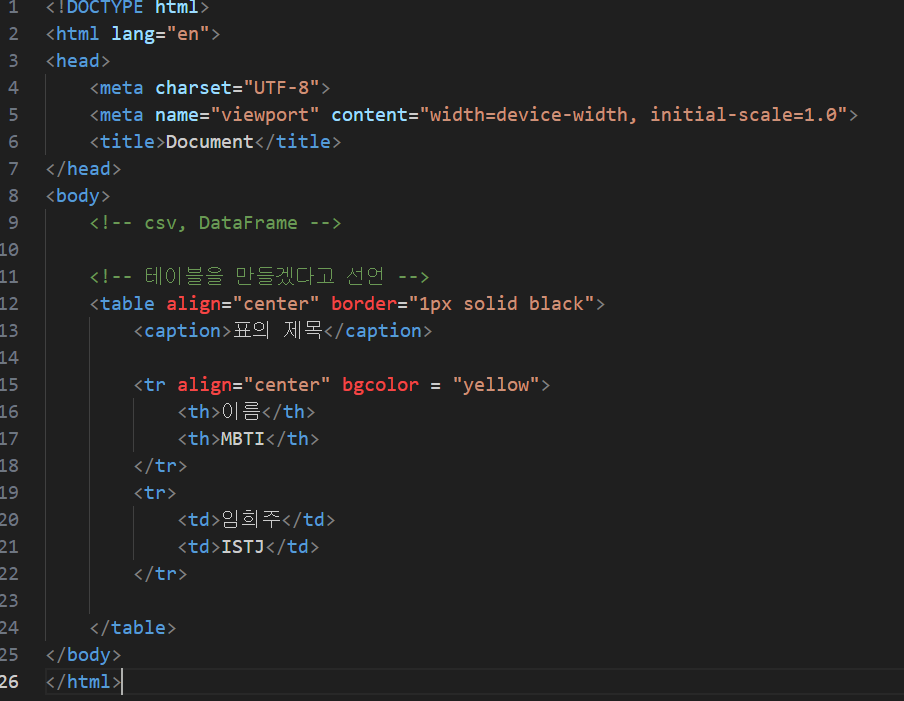
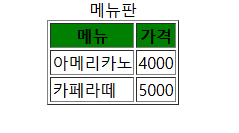
결과:

7) 테이블 태그2
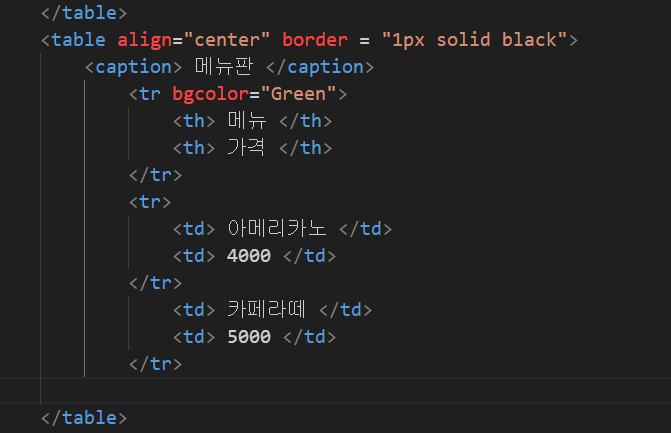
결과:
8) span함수

결과:

9) 테이블 태그 & span함수
결과:

느낀점: 이번에는 HTML 파일을 다루며 직접 웹페이지도 만들고, 테이블도 만들어보며 정말 재미있었다. Frontend가 적성일지도...? ㅋㅋ 크롤링과 스크랩핑도 배우며, 이러한 정보들을 앞으로 있을 미니 프로젝트에 어떻게 활용해야 할 지에 대해 생각도 좀 했던것 같다. 정보들을 수집하고 가공하여 내가 HTML을 수정하여 만든 나만의 웹페이지에 저장하여 제 2의 결과물을 만들어 낼 수 있을것 같다. 내일도 열심히 공부하자. <strong> 화이팅! </strong>
'[HARMAN] 세미콘 아카데미 > 공부내용' 카테고리의 다른 글
| [Harman 세미콘 아카데미] Day_9(Python) (0) | 2025.02.16 |
|---|---|
| [Harman 세미콘 아카데미] Day_8 (Python) (0) | 2025.02.13 |
| [Harman 세미콘 아카데미] Day_6 (Python 기초) (0) | 2025.02.11 |
| [Harman 세미콘 아카데미] Day_5 (Python 기초) (0) | 2025.02.11 |
| [Harman 세미콘 아카데미] Day_4 (Python 기초) (0) | 2025.02.09 |