오늘의 배움은 프레임 라이브러리인 pandas 부터 시작을 하겠다.
pandas는 데이터 분석과 처리를 위한 강력한 라이브러리로,
행(Row)와 열(Column) 구조의 데이터로 대규모 데이터 분석, 통계처리, 데이터 시각화에 사용된다
사용하기 위해서는 pandas를 설치하고 import하기만 하면 된다
설치 명령어
- !pip3 install pandas
사용하기 위한 명령어
- import pandas as pd # 자주 사용할 예정이기에 간결하게 pd로 줄였다
pandas의 기능 중,
시리즈와 비슷한 1차원 데이터 구조를 갖는 Series()는 하나의 열과 인덱스로 구성된다.
형태는 pd.Series([10,20,30,40,50])로 출력을 하면 아래와 같이 인덱스와 열을 출력한다.

DataFrame: 테이블 구조 데이터 활용하고, 2차원 데이터 구조(엑셀표와 유사)이다.
여러개의 시리즈(열)로 구성되어 있다.
형태: df = pd.DataFrame(data)

DataFrame의 기능에도 여러개가 있다.
1) 데이터프레임 상위 5개 정보 확인
print(df.head())
2) 데이터프레임 하위 5개 정보 확인
print(df.tail())
3) 데이터프레임 데이터 중 1개의 랜덤 데이터 추출
print(df.sample())
4) 데이터프레임 총 정보
print(df.info())
5) 데이터프레임 묘사 -> 데이터 통계를 숫자로 출력
print(df.describe())

DataFrame 또한 인덱싱과 슬라이싱도 가능하다!!
원하는 데이터를 추출하여 DataFrame의 형태로 표현이 가능하다 (보기 편하다)

loc(location) : 조건에 맞는 데이터 추출
형태: 데이터프레임명.loc[행 인덱스]
ex) df.loc[3]
데이터프레임명.loc[행 인덱스, 열 인덱스]
ex) print(df.loc[3, "Age"])
loc 슬라이싱 (인덱스 번호, 컬럼명 됨)
ㄴ형태 : .loc[시작(포함):끝(포함)]
리스트 슬라이싱 하듯이 loc 또한 슬라이싱하면 됩니다~
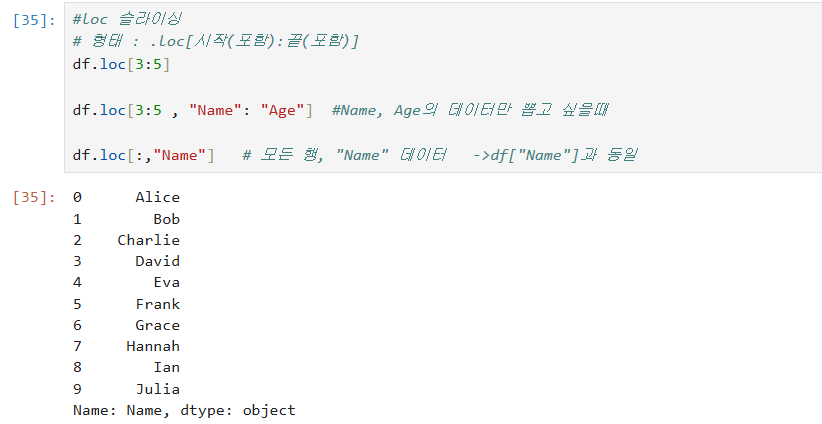
loc를 사용하는 제일 중요한 이유는 여기있다. 바로바로
Boolean Indexing : True, False를 활용한 데이터 추출이 가능하다!
예를 들어,
"Age"에 대한 여러 정보들이 들어있는 DataFrame에 df.["Age"] >= 30 을 하면 True/False의 형태로 나타나고,
df.loc[df.["Age"] >= 30]을 하면 True인 애들만 나타나게 된다.

이를 활용하여, 데이터를 거르거나 추출하는데 활용할 수 있다.
(중요) Boolean Indexing에서는 and와 or 대신 '&' , '|' 사용
ex) df.loc[(df["Age"] >= 30) & (df["City"] == "Busan")]
loc와 비슷한 iloc도 존재한다.
iloc (integer location) : loc와 기능이 거의 흡사하고, 행과 열을 모두 정수로 사용한다. 조건에 맞는 데이터를 추출한다.
loc와 슬라이싱 방법이 비슷하다.

ex) df.iloc[3]
print(df.iloc[3,1])
print(df.iloc[3:5]) # slicing: 시작 포함, 끝 미포함
print(df.iloc[3:6,0:2])
print(df.iloc[:,:]) # 모든 데이터
df.iloc[:,2] ->df[2] (불가능)
iloc은 boolean indexing 불가능!
RDBMS(관계형 데이터베이스 관리 시스템) :
정보를 얻고자 할 때, 질문(Query)
조회관련된 문법 select문
6개의 절 : SELECT, FROM, WHERE, HAVING, GROUP BY, ORDER BY
그 중, Group by를 가장 많이 사용한다. (쓰이는 부분이 많아서)
group by: 특정 기준(열)으로 그룹화하여 통계 계산, 그룹 함수도 사용 가능하다.
ex) print(df.groupby("City")["Age"].mean())
- group by("City"), 같은 도시별로 묶어라
- ["Age"], "Age" column만 인덱싱
- mean() : 평균값 구하기

이러한 함수들을 그룹화 시켜 사용하는 함수를 그룹 함수/ 집계 함수라고한다.
무슨 뜻이냐면, 여러 정보를 한꺼번에 함수에 적용하고 싶을때 사용하고 Agg 함수라고 칭한다.
형태는 .agg(["count","sum" ])이다.

배운 내용들을 사용하여 원하는 데이터만 추출하는 filtering도 가능하다

데이터를 변환하는 함수도 존재한다. 바로, apply() 함수이다. 이 함수를 사용함으로 전체 열에 적용 가능하다.
형태는 .apply(함수명) ex) df4["Name"] = df4["Name"].apply(함수명)

lambda : 함수를 간단하게 정의 후 사용
ㄴ 함수를 정의해서 apply해서 사용하는것 보다 빠름
형태: lambda 매개변수 : 표현식
ex) df4["Name"].apply(lambda x : x.upper()) -> Name에 대한 값들을 대문자로 변경해 적용한다

데이터프레임을 복사하는 방법에는 2가지 방법이 있다.
얕은 복사: 주소값이 복사
list1 = [10, 20, 30]
list2 = list1
list1[0] = 100
print(list2) -> [100, 20, 30]
------> 값이 하나만 변해도 두개 다 바뀜
깊은 복사 : 원본 유지, 백업본 필요할 시
df6 = df4.copy()
**df4의 현재 상태만 복사함 !!

결측치에 대한 함수도 존재한다.
1) .fillna() : 결측치 채우기, 조건에 부합하게 채움
ex) df6["City"].fillna("ABC", inplace = True)
2) .dropna() : 결측치 비우기, 조건에 부합하지 않으면 다 지워버림
ex) df7.dropna(inplace = True)

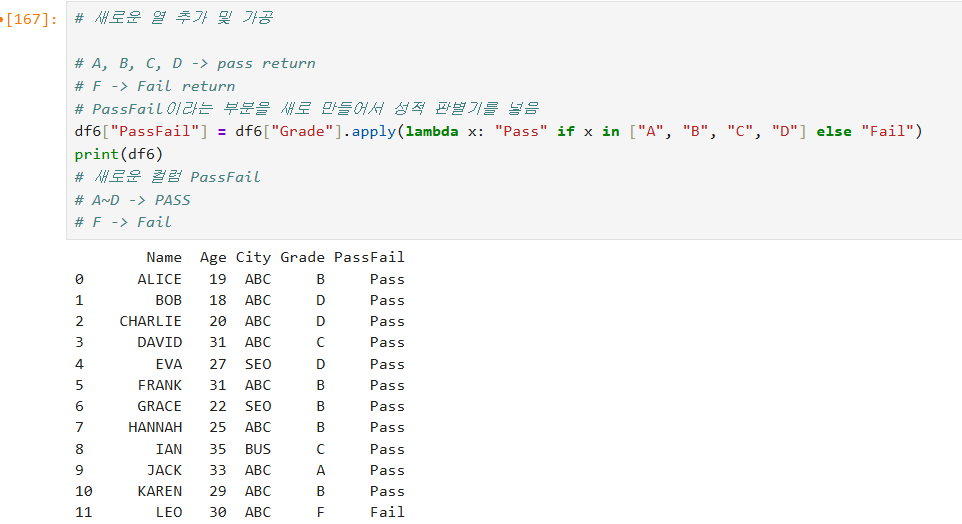
pandas의 Dataframe의 전체적인 기능들에 대한 실습 예제이다.

다음은 데이터 시각화이다.
가장 먼저 떠오르는 matplotlib, 데이터를 다양한 방법으로 도식화 하는 라이브러리 이다.
설치 방법
- !pip3 install matplolib
활용 방법
- import matplotlib.pyplot as plt
1) 선 그래프(Line Plot)
예제)
ㄴ 형태 : plt.plot(x,y,marker = "")
x = [1,2,3,4,5]
y = [10,20,25,30,40]
plt.plot(x,y,marker = "^") #선 그리기, marker = ""로 마킹 그림 바꿈
plt.title("Simple Line Graph") #제목 작성
plt.xlabel("x",fontsize = 13, color = "#ff69b4") # 라벨작성
plt.ylabel("y",fontsize = 13, color = "#ff69b4")
plt.grid(True) #격자 생성
plt.show() #그래프 표출

2) 막대 그래프(Bar Plot)
예제)
ㄴ 형태 : plt.bar(x,y)
plt.bar(dept, df_salary)
plt.title("Depart's avg Salary")
plt.xlabel("Department")
plt.ylabel("avg Salary")
plt.show()

3) 파이 차트(Pie Chart)
ㄴ 형태 : plt.pie(size, labels = "", autopct = "%1.1%%",startangle = 90)

4) 산점도 : 얼마나 흩뿌려져 있는지 확인
ㄴ 형태: plt.scatter()

5) 히스토그램
##### 기초 통계 분석 #####
우리가 지금까지 배운 내용들은 자료에 대해 통계를 내고 분석하기 위함이다.
기술 통계량을 확인하기 위해 아래와 같은 함수들을 활용하기도 한다.
- count() : 데이터 개수 확인
- mean() : 평균 구하기
- std() : 표준편차 구하기
- min ~ max : 최소값, 최대값
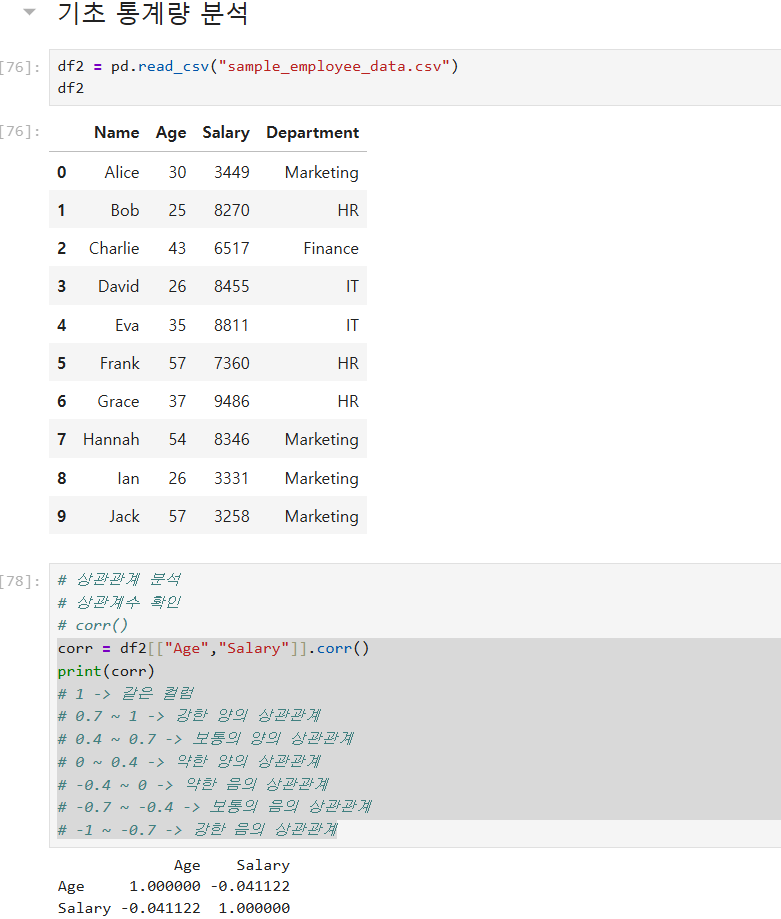
이제 상관계수를 분석하기 위해 corr()함수를 사용한다.
Correlation Coefficient 함수는 두 변수 간의 관계를 수치로 표현하고
1에 가까울수록 양의 상관관계, -1에 가까울수록 음의 상관관계이다.
# 1 -> 같은 컬럼
# 0.7 ~ 1 -> 강한 양의 상관관계
# 0.4 ~ 0.7 -> 보통의 양의 상관관계
# 0 ~ 0.4 -> 약한 양의 상관관계
# -0.4 ~ 0 -> 약한 음의 상관관계
# -0.7 ~ -0.4 -> 보통의 음의 상관관계
# -1 ~ -0.7 -> 강한 음의 상관관계
데이터의 음/양을 보고 상관관계에 대해 유추가 가능하다는 것이다.
이러한 상관관계를 시각화해주는 라이브러리도 있다. (Python은 참 친절하다)
바로 : Seaborn ,,, 무려 히트맵을 보여준다
설치 방법
- !pip3 install seaborn
사용 방법
- import seaborn as sns
히트맵으로 보기:
sns.heatmap(corr3,annot= True, cmap="coolwarm", fmt = ".2f")
#출력 옵션, annot = 상관계수 값 출력

Seaborn을 이용해 출력된 히트맵을 통해 x축의 인자와 y축의 인자를 아래와 같이 비교하여 상관관계를 알아낸다.
- 진한 빨간색(+) : 강한 양의 상관관계
- 진한 파란색(-) : 강한 음의 상관관계
- 흰색(0 근처) : 상관관계 거의 없음
오늘 배운것들을 통해 실데이터인 Titanic 탑승자에 대한 정보를 활용해 실습을 하였다.




*Corr()함수의 경우 int or float 형태로 상관관계를 만들기 때문에,
"male", "female" 문자열을 갖는 "Sex"의 경우, boolean indexing으로 남자면 1, 여자면 0의 정수 형태로 변환한다.
정수로 변환된 성별에 대한 정보를 heatmap에 추가하여 상관관계를 파악한다.
느낀점: 데이터에 대한 예제들과 시각화에 대해 많이 배우게 되었다. Python 관련한 프로젝트를 하게 될 예정인데, 오늘 배운 내용들을 잘 활용하여 프로젝트 발표 시, 자료를 시각화 하는데 잘 사용해야겠다.
'[HARMAN] 세미콘 아카데미 > 공부내용' 카테고리의 다른 글
| [Harman 세미콘 아카데미] Day_8 (Python) (0) | 2025.02.13 |
|---|---|
| [Harman 세미콘 아카데미] Day_7 (Python) (0) | 2025.02.12 |
| [Harman 세미콘 아카데미] Day_5 (Python 기초) (0) | 2025.02.11 |
| [Harman 세미콘 아카데미] Day_4 (Python 기초) (0) | 2025.02.09 |
| [Harman 세미콘 아카데미]Day_3(Python 기초) (1) | 2025.02.06 |