[Harman 세미콘 아카데미] Day_10(Python)
간만에 월요일... 항상 월요일은 쉽지 않다.
오늘은 데이터 베이스에 관해 공부하였다.
데이터베이스란?
데이터를 저장/관리 하는 시스템으로, 대량의 데이터를 효율적으로 저장하고 검색하는데 사용된다.
그 중, 우리가 사용할 SQLite, 상대적으로 가볍고, 설정이 필요 없는 파일 기반의 데이터베이스이다.
SQLite 데이터베이스는 우리가 아는 .db확장자로 저장이 되고, CREATE TABLE로 테이블을 생성한다.
데이터베이스를 연결하기 위해 4가지 과정을 거친다.
1) DataBase 통로 생성 :
ㄴ -> DB 경로(URL), 권한(접근하고자 하는 ID,PW)
ㄴ sqlite3.connect("DB파일")
2) SQL (Structed Query Language) 통로 생성
ㄴ 질의를 전달하고 결과를 돌려 받는 통로
ㄴcurs = con.cursor()
3) CRUD(Create, Read, Update, Delete) 작업
ㄴ ex) Create 작업
ex) 만약 테이블이 없다면 만들어라
ㄴ CREATE TABLE IF NOT EXISTS 테이블명
sql = """
CREATE TABLE IF NOT EXISTS contact(
name TEXT,
age INTEGER,
email TEXT
)
"""
4) 통로 닫기 (역순으로 닫기)
ㄴcurs.close() # SQL 통로 닫기
ㄴcon.close() # Database 통로 닫기


데이터 베이스를 위한 테이블 생성 예제; 제약 조건에 대해 배웠다.


이렇게 생성된 데이터 베이스는 pandas를 통해 직관적으로 테이블을 확인하여 우리눈으로 보기 편하게 할 수 있다.

그리고, result = curs.fetchall() 함수를 통해 파일을 직접 열어볼 수 있다.

자, 이제 데이터베이스를 열어보고 접근하는 법을 배웠으니, 명령어를 통해 원하는대로 사용하자.
이러한 명령어들은 3단계인 CRUD 작업 방식에 사용된다.

먼저, SELECT문
형태: SELECT *
FROM table;
- SELECT 절
-> 조회할 column명
-> column1, column2, ..., ...
전부 조회 : *
- FROM 절
-> 조회할 TABLE명

예제 : locations라는 테이블에서 city에 대한 정보를 불러오라~

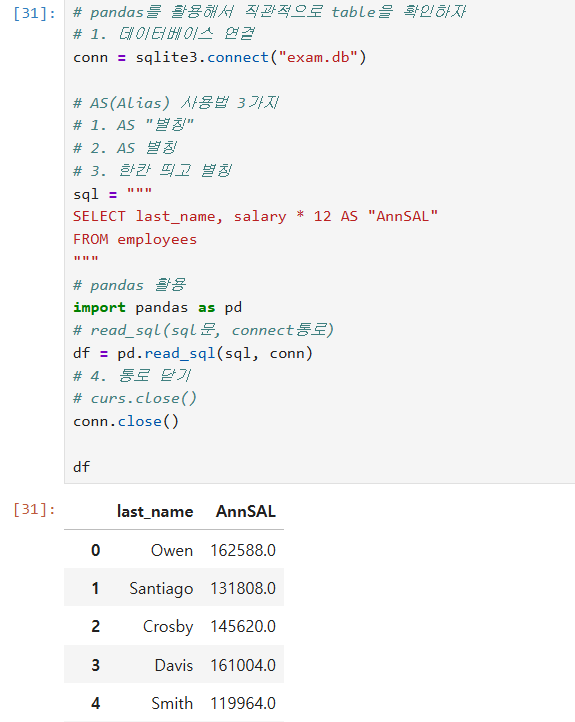
AS(alias)를 활용하여 데이터베이스의 열 머리글의 이름을 변경한다. 이를 열 별칭 정의라고 한다.
사용 방법은 1) AS "별칭"
2) AS 별칭
3) 한칸 띄우고 별칭
중복행 제거(Distinct) : 중복된 컬럼을 제거하고 Unique 값 (= 겹치지 않는 값)만 출력한다.
ex) 형태: sql = """
SELECT DISTINCT department_id
FROM employees
"""
----> employees 테이블에 겹치지 않는(= 중복 행을 제거한) department_id를 출력한다.

WHERE 절: 조건을 나타내는 연산자
ex) 형태: sql = """
SELECT last_name
FROM employees
WHERE last_name = 'Owen'
"""
----> SQL문에서 문자열이나 날짜를 표기할 때는 ' ' 사용

비교 연산자를 활용하여 WHERE의 조건을 더욱 풍성하게(?) 할 수 있다.




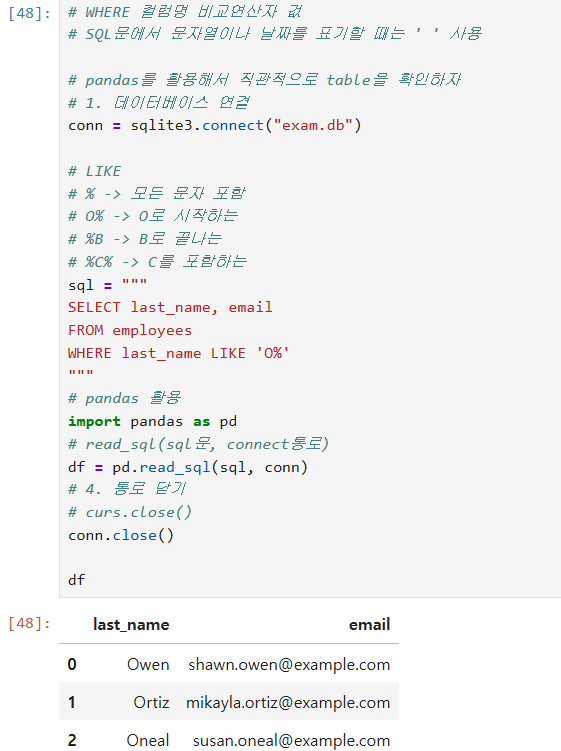
LIKE 조건문: 문자 패턴에 대해 확인한다.
# % -> 모든 문자 포함
# O% -> O로 시작하는
# %B -> B로 끝나는
# %C% -> C를 포함하는
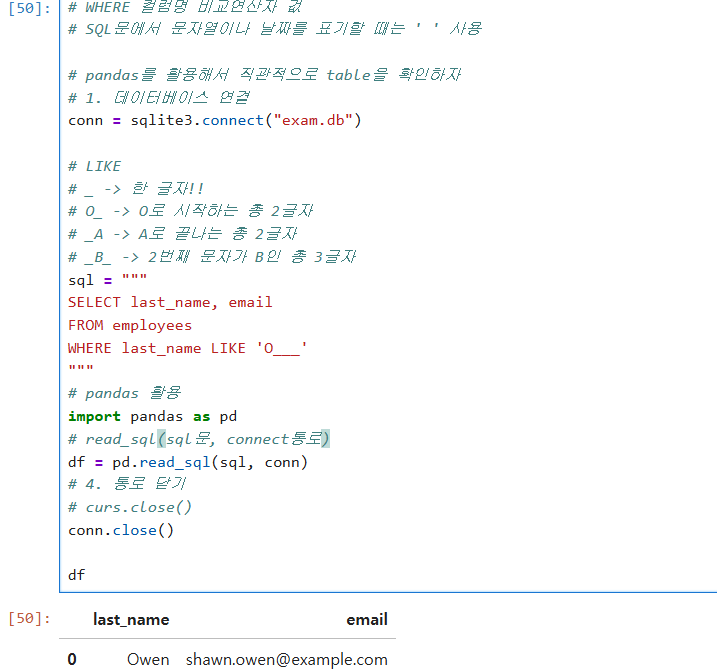
# _ -> 한 글자!!
# O_ -> O로 시작하는 총 2글자
# _A -> A로 끝나는 총 2글자
# _B_ -> 2번째 문자가 B인 총 3글자
ORDER BY 절: 결과를 정렬한다(오름차, 내림차)
- Ascending: 오름차순 (ASC) & (생략 시 발동)
- Descending: 내림차순 (DESC)
형태 : sql = """
SELECT last_name, salary
FROM employees
ORDER BY salary DESC
"""

위에서 배운 내용들을 토대로, SELECT문에 대해 여러 실습을 하였다. 사진과 문제를 첨부해 놓겠다.


- AS, 열 별칭



WHERE 조건문에서도 AND를 활용하여 논리 조건을 부여할 수도 있습니다.



NULL값을 활용하여, 없는 것에 대한 조건 연산도 가능하다.


ORDER BY ~ ASC를 활용하여 연봉에 대해 오름차순으로 정렬한다.

LIKE 함수를 이용하여 문자 패턴의 조건을 설정하여 정보를 걸러낸다.


IN 비교 연산자와 NOT을 활용하여 정보를 출력해낸다.

DISTINCT 활용 예제

그룹 함수(GROUP BY) : 단일 행 함수와 달리 행 집합에 작용하여 그룹 당 하나의 결과를 생성한다.
그룹 함수 종류: AVG , COUNT, MAX, MIN, SUM
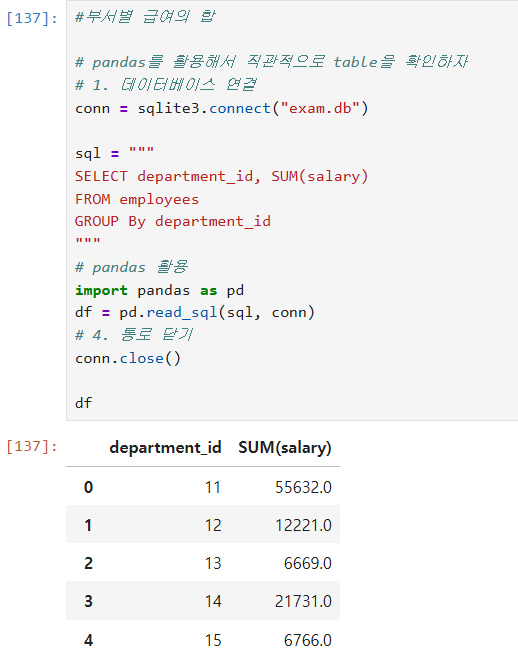
아래의 예제를 보면, GROUP BY를 통해 여러개를 묶을 경우에는 HAVING을 사용해야 한다.
HAVING 사용 방법
- WHERE 절에는 단일 열(그룹화되지 않은 열)에 대한 연산
- 그룹화된 column에 조건을 적용하기 위해서는 HAVING절 이용



COUNT를 활용한 수 세기

연산자를 활용하여 바로 계산도 가능하다

데이터베이스에 대해 배우다 보면, 여러 테이블에서 값을 가져 올 수 없을까?에 대한 생각을 하게된다.
이러한 생각은 조인을 통해 실현이 가능하다.
조인 : 여러 테이블에서 데이터 얻기
- 여러 테이블의 데이터가 필요한 경우
- 여러 테이블에 동일한 열 이름이 있는 경우 열 이름에 테이블 이름을 접두어 표시
조인의 종류:
1) 등가 조인
2) 비등가 조인
3) 포괄 조인
4) 자체 조인
조인의 방법:
N개의 테이블에서 조인이 실행될 때, N-1개의 조인조건이 필요하다.
1) 칼럼명 나열 -> SELECT절
2) 칼럼명이 속해 있는 테이블 나열 -> FROM 절
3) 테이블에 별칭 지어주자
4) WHERE절에 조인 조건을 설정하자 (등가조인 경우에만)
5) SELECT절에 표시된 칼럼들이 어느 테이블에 속하는지 명시
예제를 통해 알아보자

이 경우는 employees, departments, locations의 세 테이블에서 각각 last_name, department_name, location_id, city를 가져와야 한다. 3개의 테이블을 사용하기에 N-1인 2개의 조인 조건이 필요하다.
이번의 경우 employees 와 departments의 테이블은 department_name이 겹치고,
departments와 locations의 테이블은 location_id가 겹치게 되어 3개의 테이블을 통해 원하는 값들을 가져오게 된다.
그리하여 WHERE 조건을 통해 겹치는 부분을 표기한다.
ex) WHERE e.department_id = d.department_id
AND d.location_id = l.location_id
이때, AS로 축약된 테이블의 이름을 각 테이블에 속하는 칼럼 앞에 붙혀야한다.
ex) e.department_id , d.department_id
같은 테이블을 조인하는 특수 경우도 있다. 일반 조인과 비슷하게 사용하면 된다.

JOIN과 GROUP BY의 콜라보로도 활용이 가능하다.

Sub Query : 소괄호 안에 쿼리문을 작성하여 연산된 결과를 사용
아래 예를 들어 사용하면,
조건문인 성씨가 'Rice'인 사람과 같은 부서인 사람을 찾기 위해 'Rice'씨의 부서를 소괄호를 통해 찾는다.
찾게된 Rice씨의 부서를 활용하여, 그 부서에 있는 사번과 고용일을 구하게 되는 것이다.
이때, Rice씨 본인은 빼야하므로, <> 연산자를 활용하여 제거한다.

Sub Query문을 비교 연산자를 활용하여 바로 비교도 가능하다.

소괄호에 대해 주의할 점이 있다.
소괄호는 복합 연산을 기본으로 한다. 그리하여, 바로 아래 그림과 같이 단일 연산자인 =을 사용하게 되면 올바른 값이 출력 되지 않는다. 그리하여 복합 연산자인 IN을 사용해야 한다.



말장난 같을 수도 있지만, 소괄호 안의 소괄호를 통해 더욱 심도 깊은 조건 설정이 가능하기도 하다.

SELECT에 대한 예제들을 많이 풀다보니 CRUD의 다른 것들에 잠깐 잊고 있었다...
INSERT 문: 만들어진 테이블에 데이터를 삽입한다.
형태 : INSERT INTO 테이블명
VALUES (값)
*** 두개 이상의 컬럼에 각각 값 집어넣기
형태: INSERT INTO 테이블명(컬럼명1, 컬럼명2, ...)
VALUES(값1, 값2, ...) 두개가 순서대로 매칭
- 컬럼명을 생략하면 NULL 이때, column에 DEFAULT가 있으면 발동한다.
여기서 Transaction이라는 개념도 나오게 된다.
Transaction : 데이터 베이스의 최소 작업 단위로, 작업의 시작과 끝을 알 수 있다.
단, 작업이 끝났을 때, DB 관리자는 1) 작업 반영(commit)
2) 작업 취소(rollback)을 할 수 있다.
예를 들면, 데이터베이스에 서울 기온 정보 3개 삽입
- 1번 데이터 추가, 2번 데이터 추가, 3번 데이터 추가
- 3개의 데이터를 DB에 반영(저장) or 취소 (저장 X)-> 추가 전 상태로 돌아감

이를 확인하기 위해 'CRUD'의 Read도 활용해 보자.
READ : 데이터베이스 안에 있는 table데이터를 전부 SELECT한다 .



CRUD의 U를 맡고 있는 UPDATE
UPDATE : 데이터를 수정 (기본적으로, 전체의 데이터를 수정함)
형태: UPDATE 테이블명
SET 컬럼명 = 값


마지막으로, CRUD의 D를 맡고 있는 DELETE
DELETE : 데이터를 삭제 (기본적으로, 전체의 데이터를 삭제함)
형태: DELETE FROM 테이블명
WHERE 조건


### 만일 테이블도 지우고 싶다면 DROP TABLE 명령어를 사용하라!!!
느낀점: 데이터베이스에 대해 많이 배울 수 있었다. 30개의 예제를 풀면서 그중 2/3은 SELECT문 이였다. 그렇게 많이 풀어보니 머리에도 오래 남을 것 같다...ㅋ 까먹지 말자!